Data Migration – Oracle to Snowflake using Azure Blob Storage
Introduction
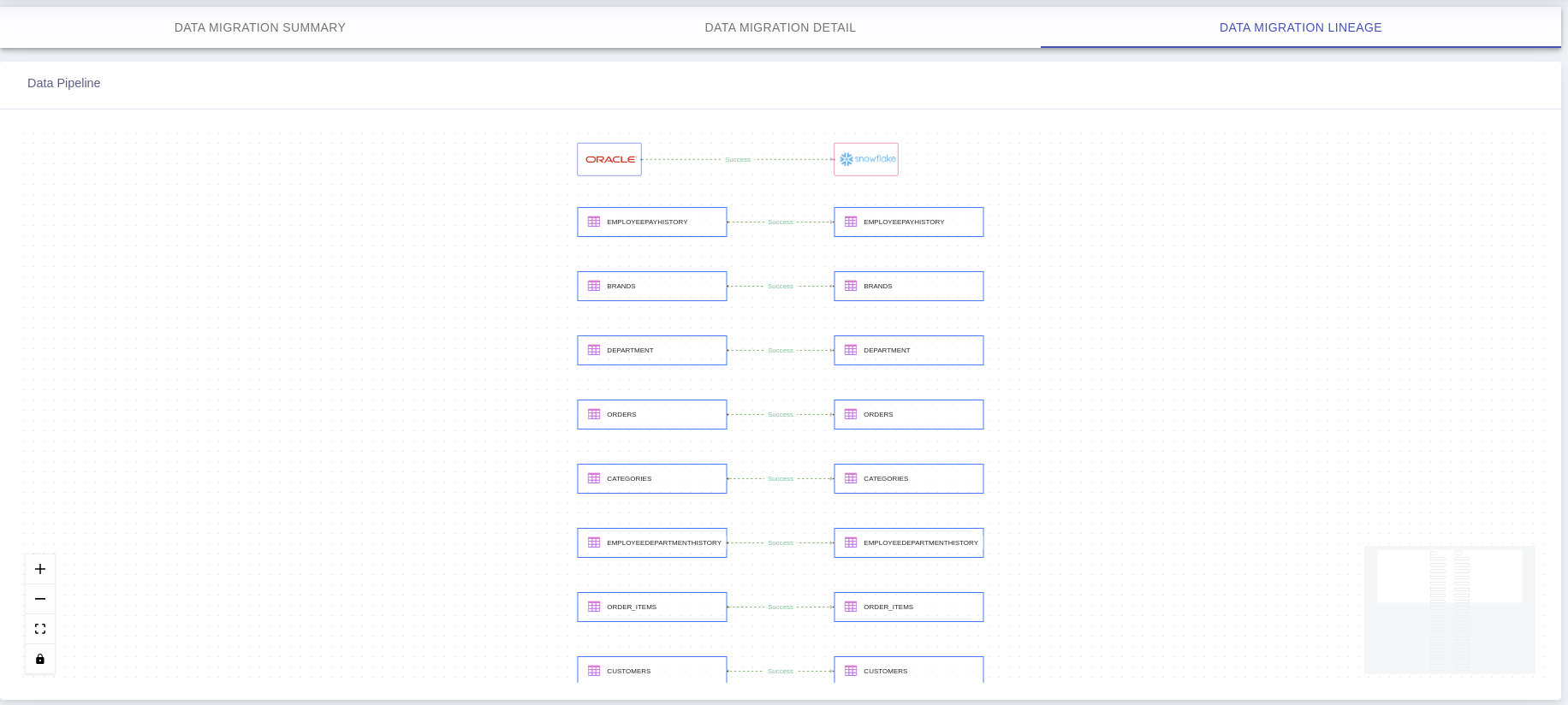
Are you trying to migrate Oracle to Snowflake? Have you looked all over the internet to find a solution for it? If yes, then you are in the right place. Snowflake is a fully managed Data Warehouse, whereas Oracle is a modern Database Management System.
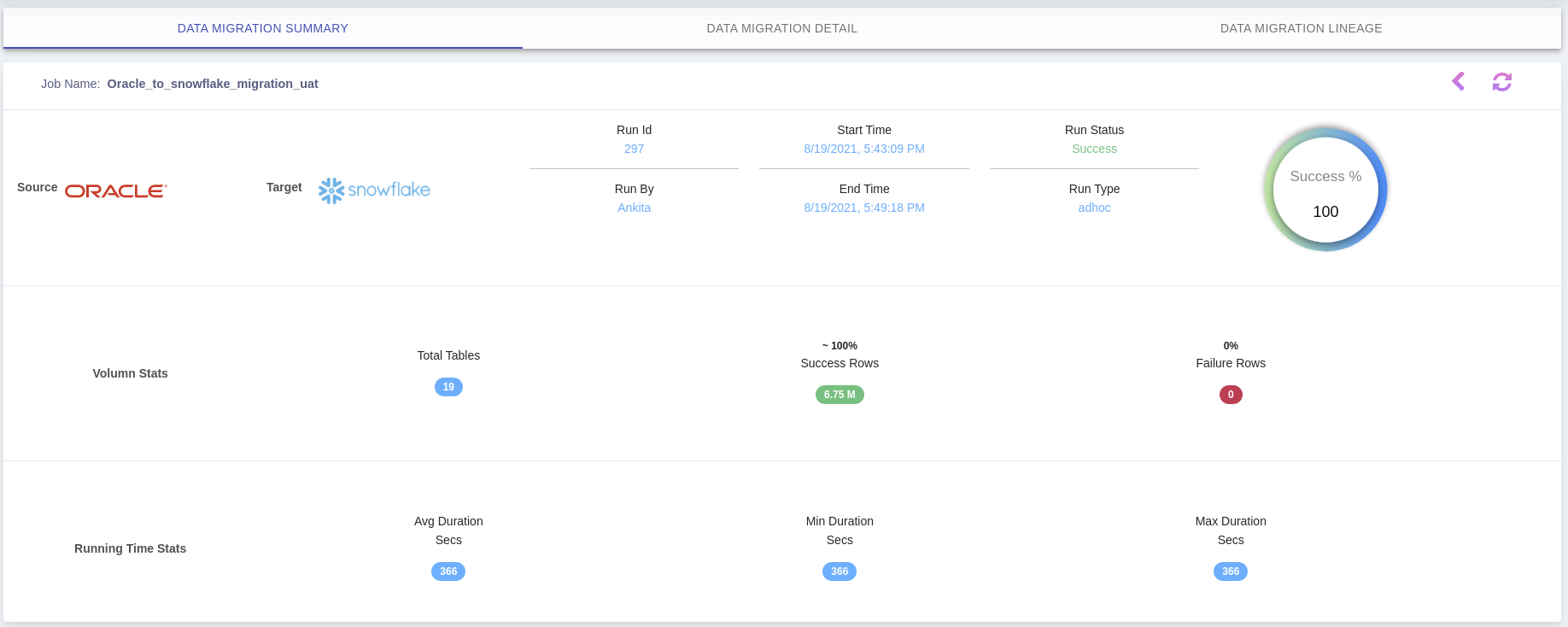
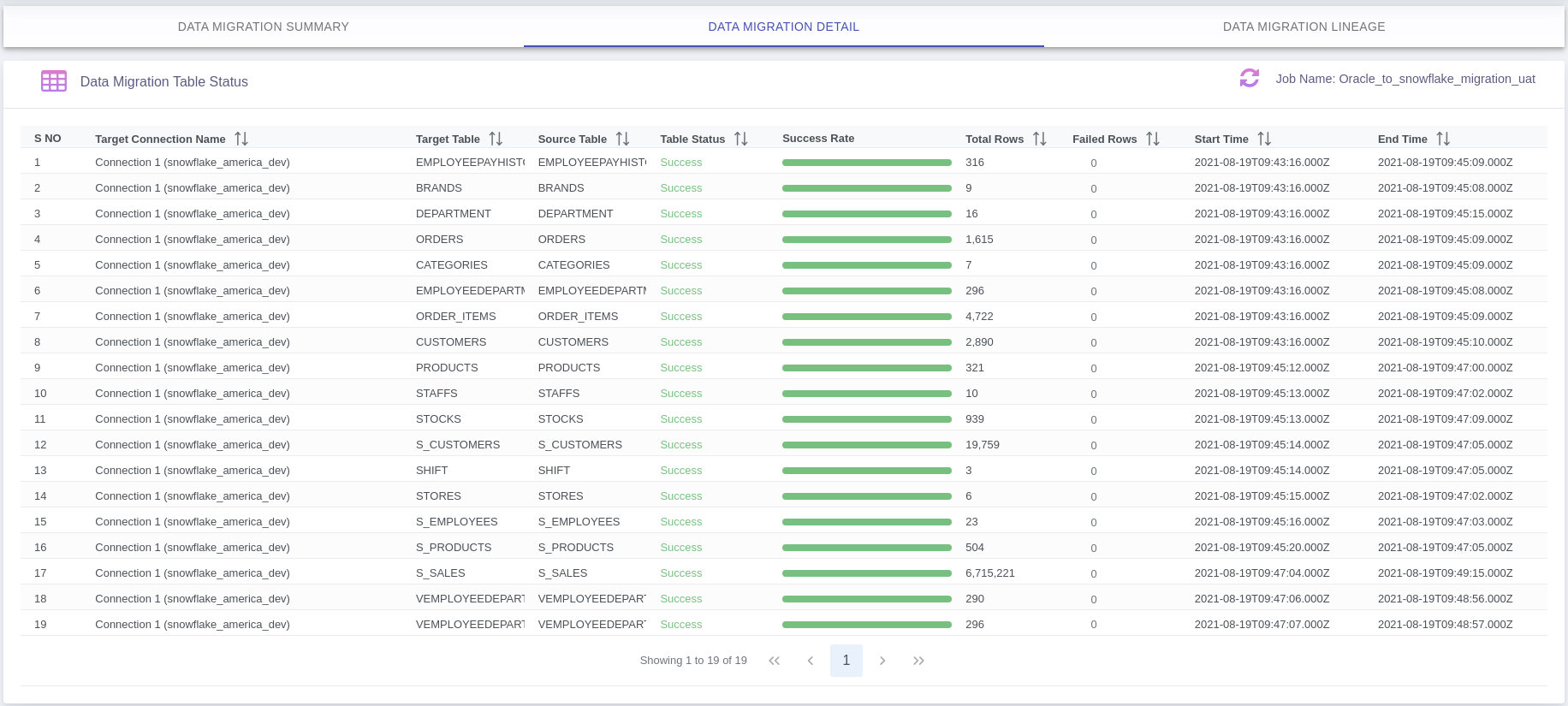
This article will give you a brief overview of migrating data from Oracle Database and Snowflake via Azure Blob stage.
What is Azure Blob stage, why do we need here:
Azure Blob – The staging area for Snowflake. This might be something created solely for use by Snowflake, but it is often already an integral part of a company’s greater data repository landscape.
Prerequisite
We need following active accounts for Oracle to Snowflake migration
- Oracle Database
- Snowflake
- Azure Blob Storage Account
To know more about Oracle Database, visit this link.
To know more about Snowflake, visit this link.
To know more about Azure Blob, visit this link
Create Connections
1. Oracle connection
uArrow has an in-built Oracle Integration that connects to your oracle database within few seconds.
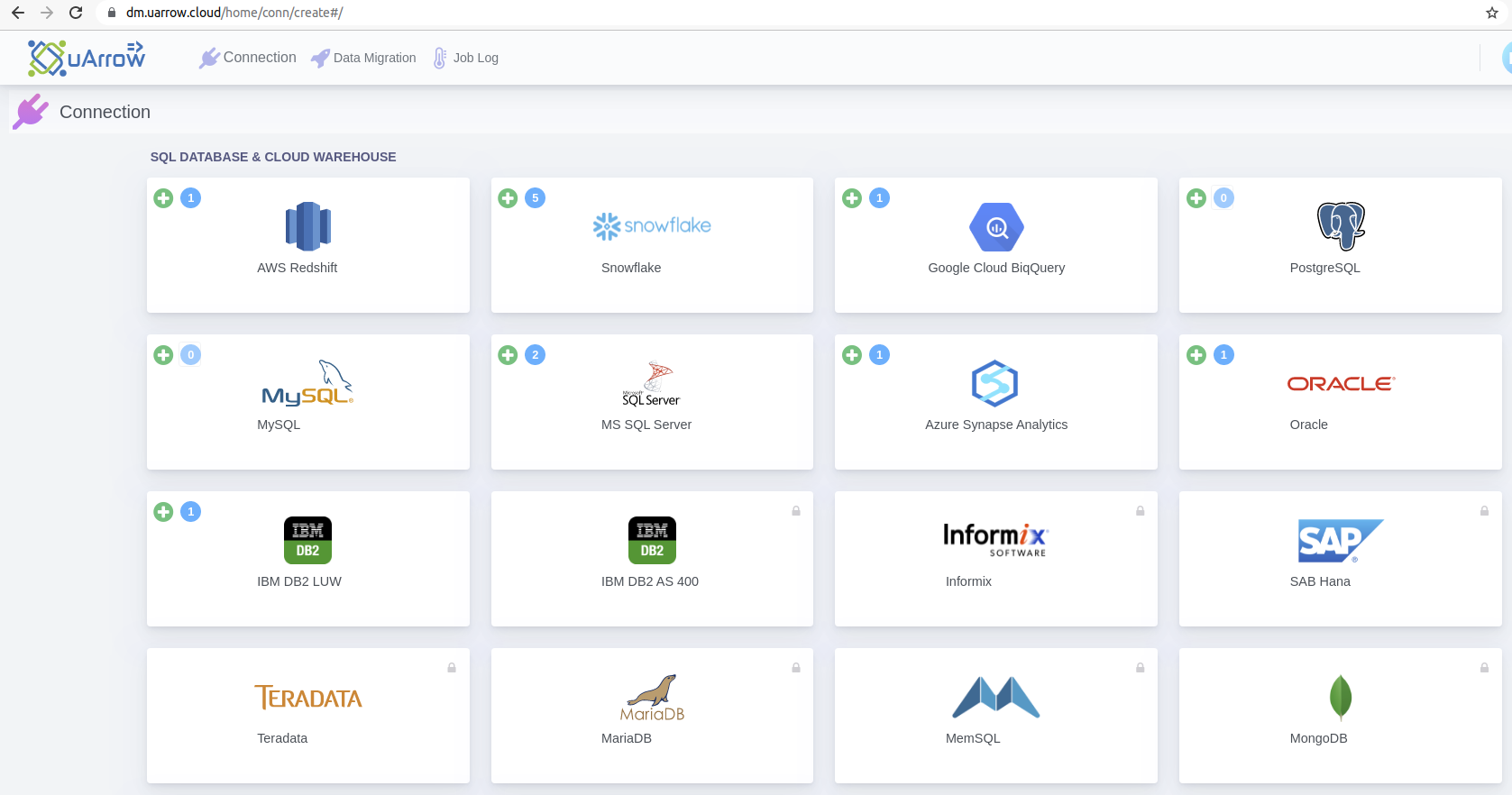
1.1. Click Connection menu from top to view (SQL DATABASE & CLOUD WAREHOUSE, CLOUD STORAGE, etc.) adapters
1.2. Click Oracle button to create Oracle database connection
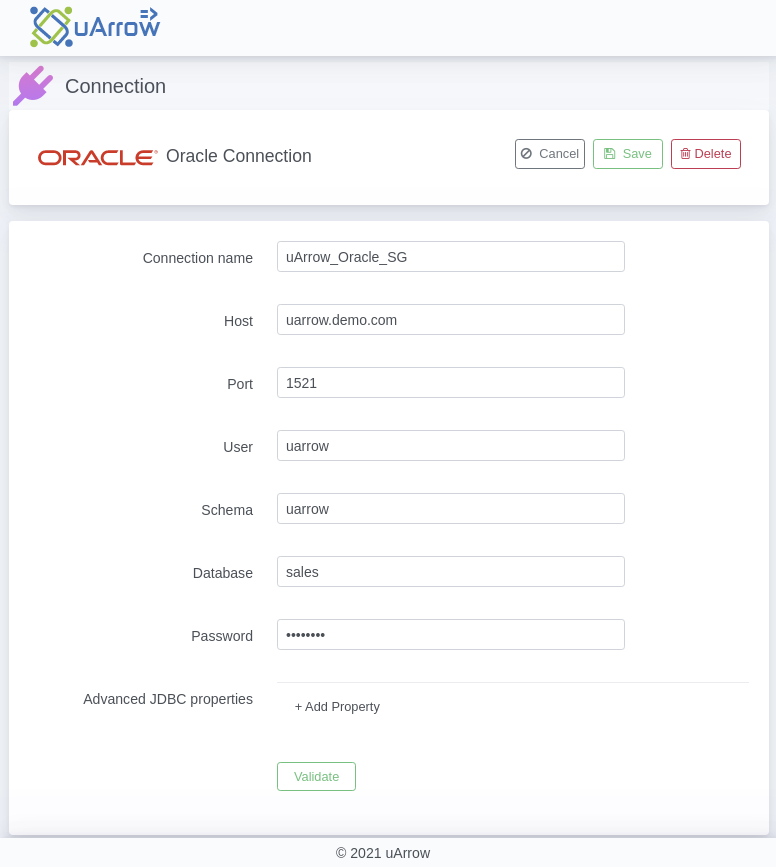
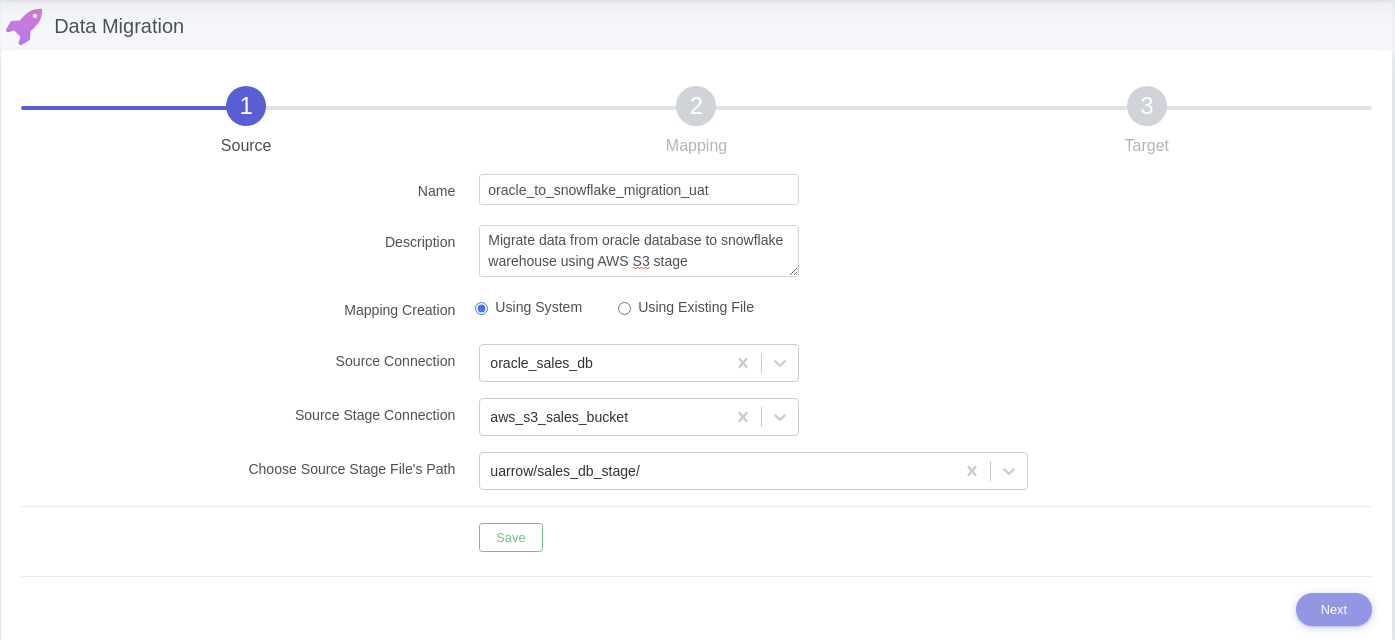
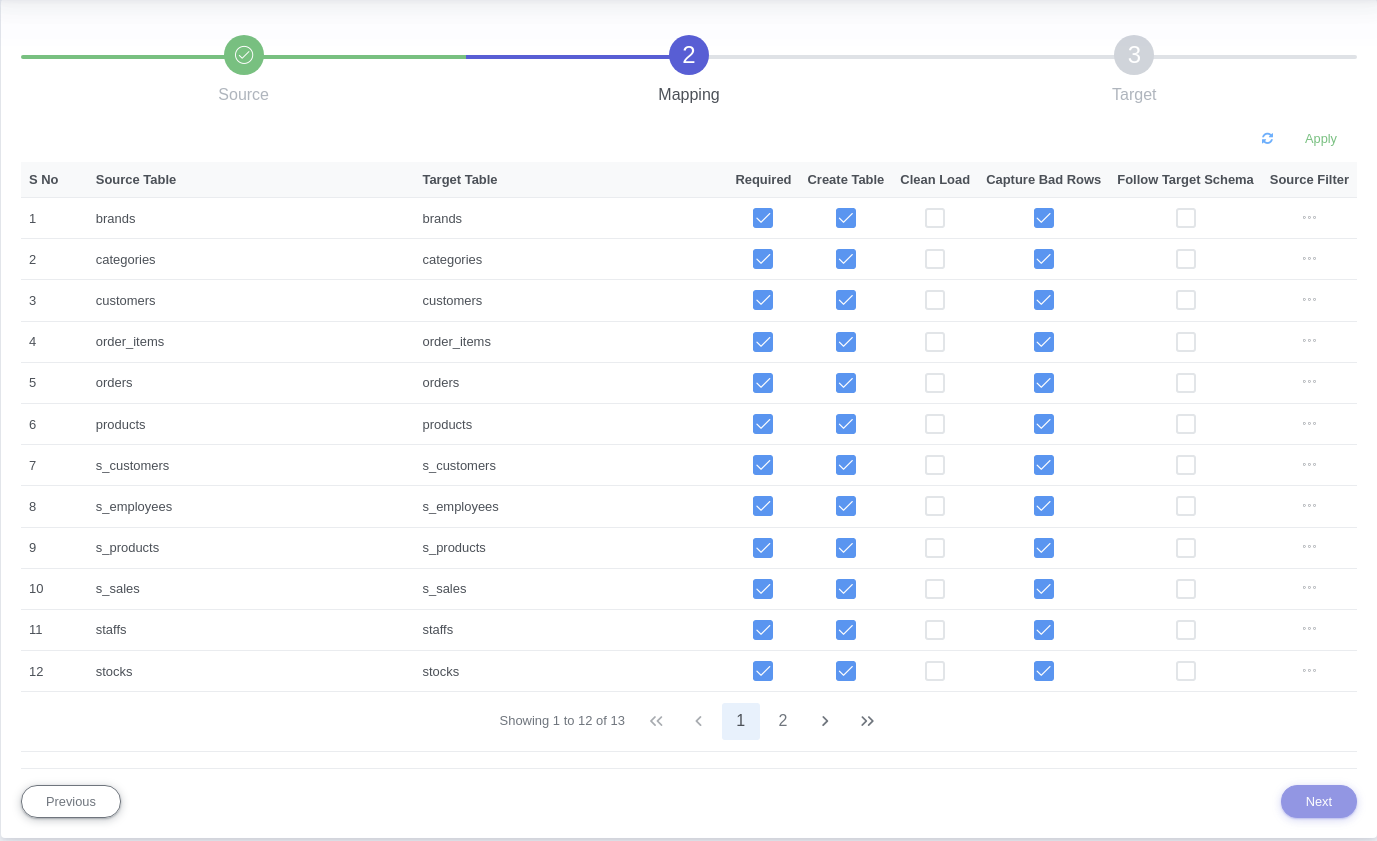
1.3. Provide below connection parameters in the connection creation form
| Parameter Name |
Description |
| Connection name |
Specify the name of the source connection. |
| Host |
Enter the name of machine where the Oracle Server instance is located, it should be Computer name, fully qualified domain name, or IP address |
| Port |
Enter the port number to connect to this Oracle Server. Four digit integer, Default: 1521 |
| Database |
Enter an existing Oracle connection through which the uArrow accesses sources data to migrate. |
| Schema |
Enter an existing Oracle database schema name. |
| User |
Enter the user name of the oracle database, The user name to use for authentication on the Oracle database |
| Password |
Enter the user’s password. The password to use for authentication on the Oracle database |
1.4. After connection details, validate connection to verify

1.5. Save Connection – Don’t forget to save connection after connection validation success.
2. Azure Blob storage connection
uArrow has an in-built Azure Blob Integration that connects to your Azure Blob within few seconds.
2.1. Click Connection menu from top to view (SQL DATABASE & CLOUD WAREHOUSE, CLOUD STORAGE, etc.) adapters
2.2. Click Azure Blob Storage button to create Oracle database connection
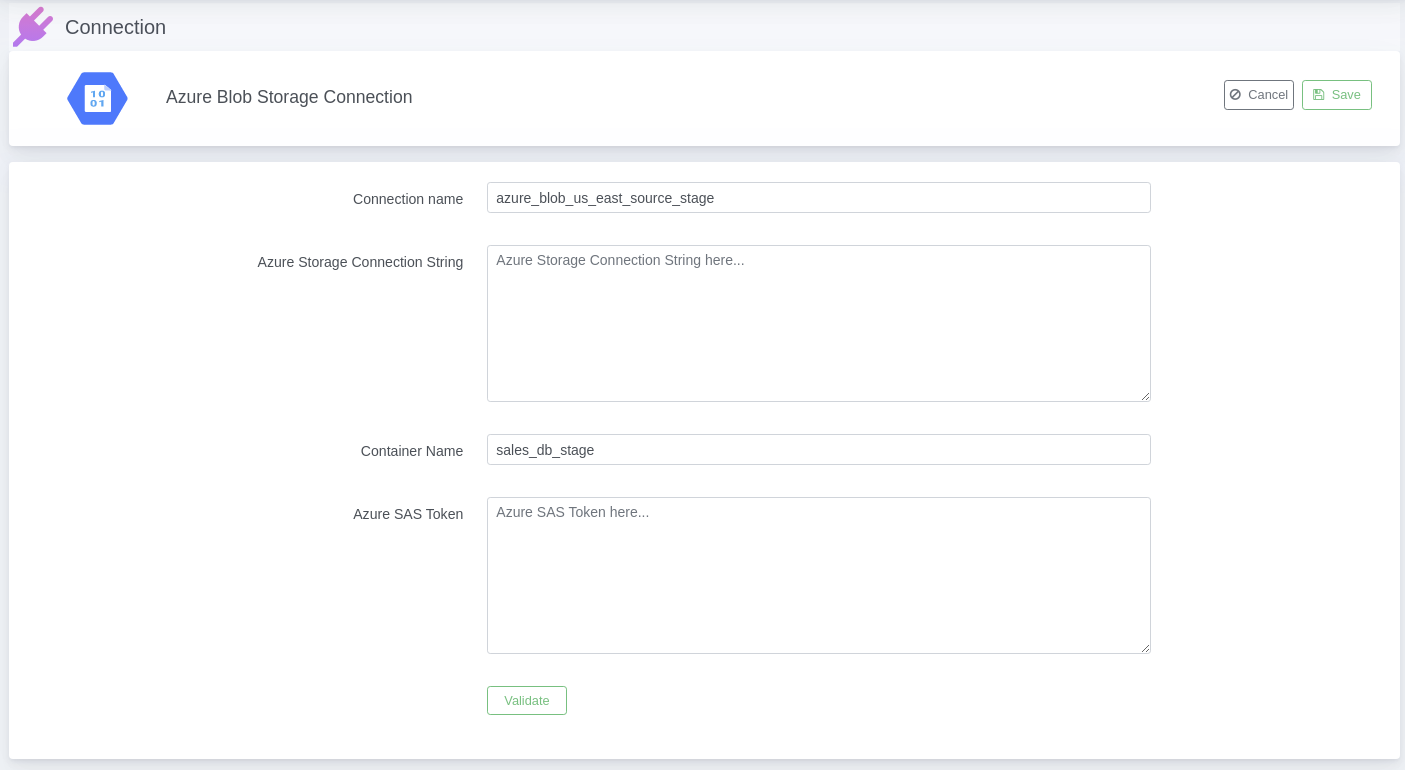
2.3. Provide below connection parameters in the connection creation form
| Parameter Name |
Description |
| Connection name |
Specify the name of the stage connection. |
| Container Name |
Specify your existing azure blob container name. |
| Azure Storage Connection String |
Specify the azure storage connection string for your Amazon Web Services account.
Refer link |
| Azure SAS Token |
Specify the azure SAS token for your azure blob container.
Refer here to generate SAS token for azure blob container |
2.4. After connection details, validate connection to verify

2.5. Save Connection – Don’t forget to save connection after connection validation success.
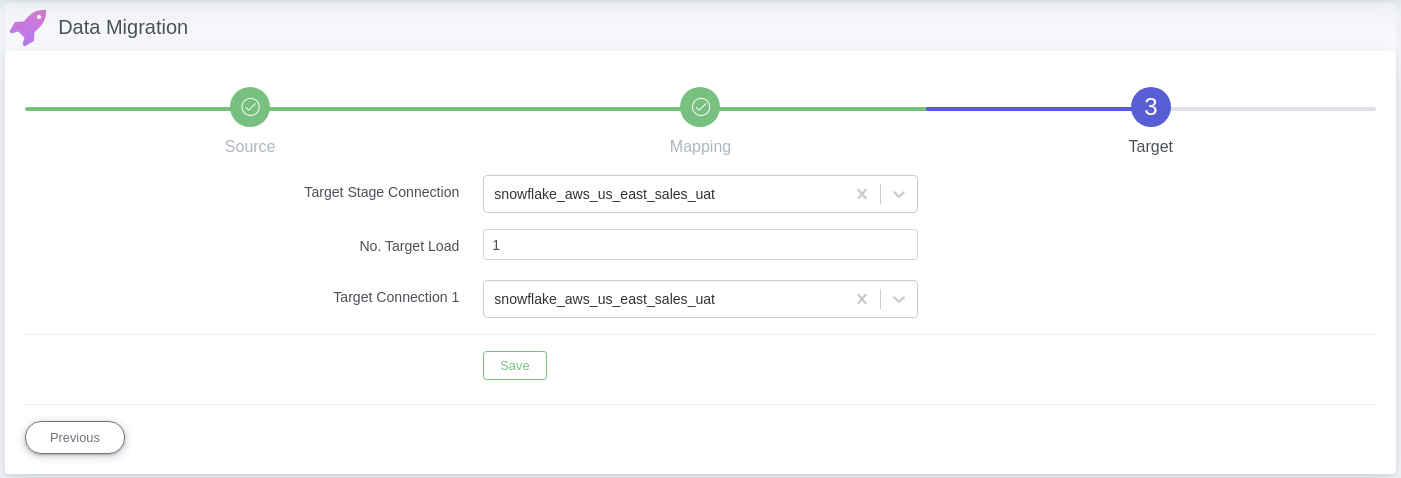
3. Snowflake connection#
uArrow has an in-built Oracle Integration that connects to your oracle database within few seconds.
3.1. Click Connection menu from top to view (SQL DATABASE & CLOUD WAREHOUSE, CLOUD STORAGE, etc.) adapters