Data Migration – AWS S3 to Redshift warehouse
Introduction
Are you trying to migrate AWS S3 Data to Redshift? Have you looked all over the internet to find a solution for it? If yes, then you are in the right place. This article will give you a brief overview of migrating data from AWS S3 to Redshift.
Prerequisite
We need following active accounts for AWS S3 to Redshift migration Redshift AWS S3 Bucket (Optionally you can use uArrow AWS S3 Bucket)
Create Connections
1. AWS S3 connection
uArrow has an in-built AWS S3 Integration that connects to your AWS S3 within few seconds. 1.1. Click Connection menu from top to view (SQL DATABASE & CLOUD WAREHOUSE, CLOUD STORAGE, etc.) adapters
1.2. Click AWS S3 button to create AWS S3 connection.

1.3. Provide below connection parameters in the connection creation form
| Parameter Name | Description |
|---|---|
| Connection name | Specify the name of the stage connection. |
| Bucket Name | Specify your AWS S3 name. |
| Access Key | Specify the access key for your Amazon Web Service account. |
| Secret Key | Specify the secret key for your Amazon Web Service account. |
| Region | The region where your bucket should be located. For example, us-east-1 |
| S3 URI | Specify AWS bucket URL |
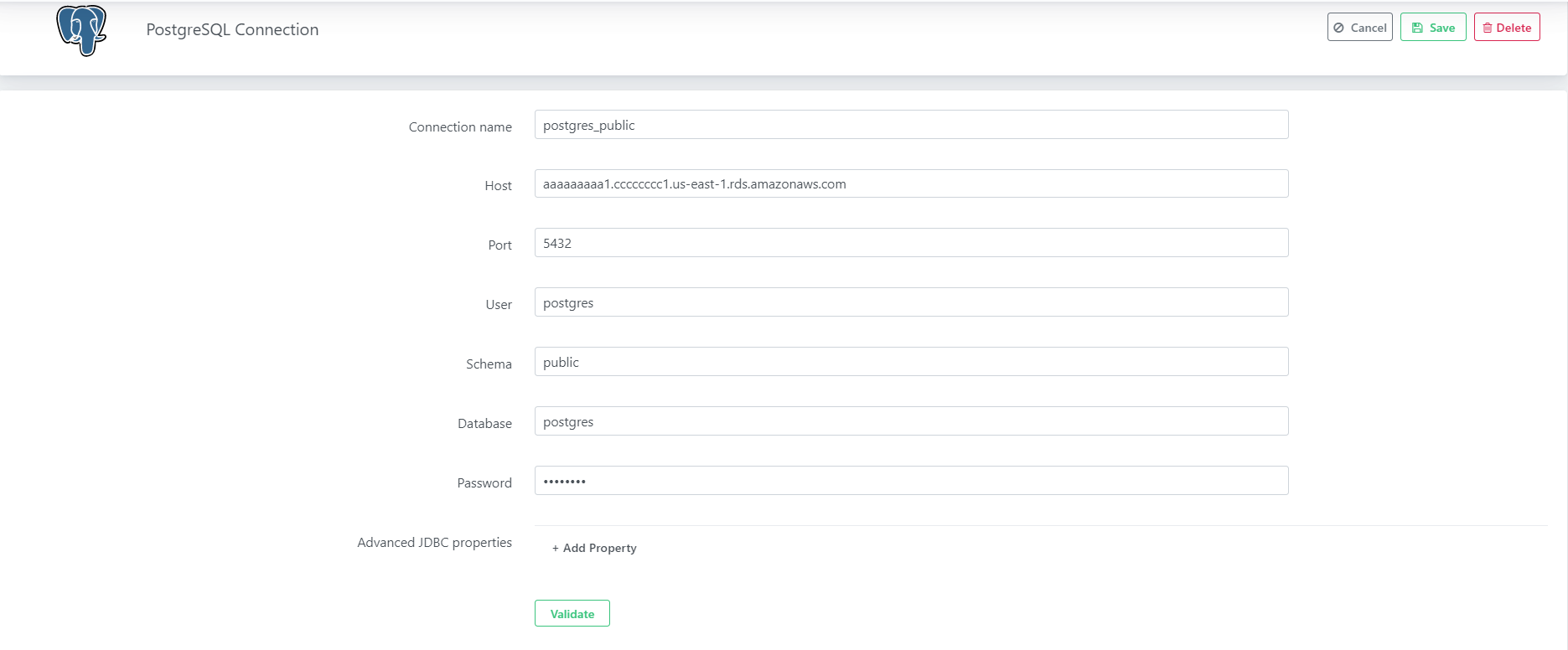
1.4. After connection details, validate connection to verify.

2. Redshift connection
uArrow has an in-built Redshift Integration that connects to your Redshift database within few seconds.
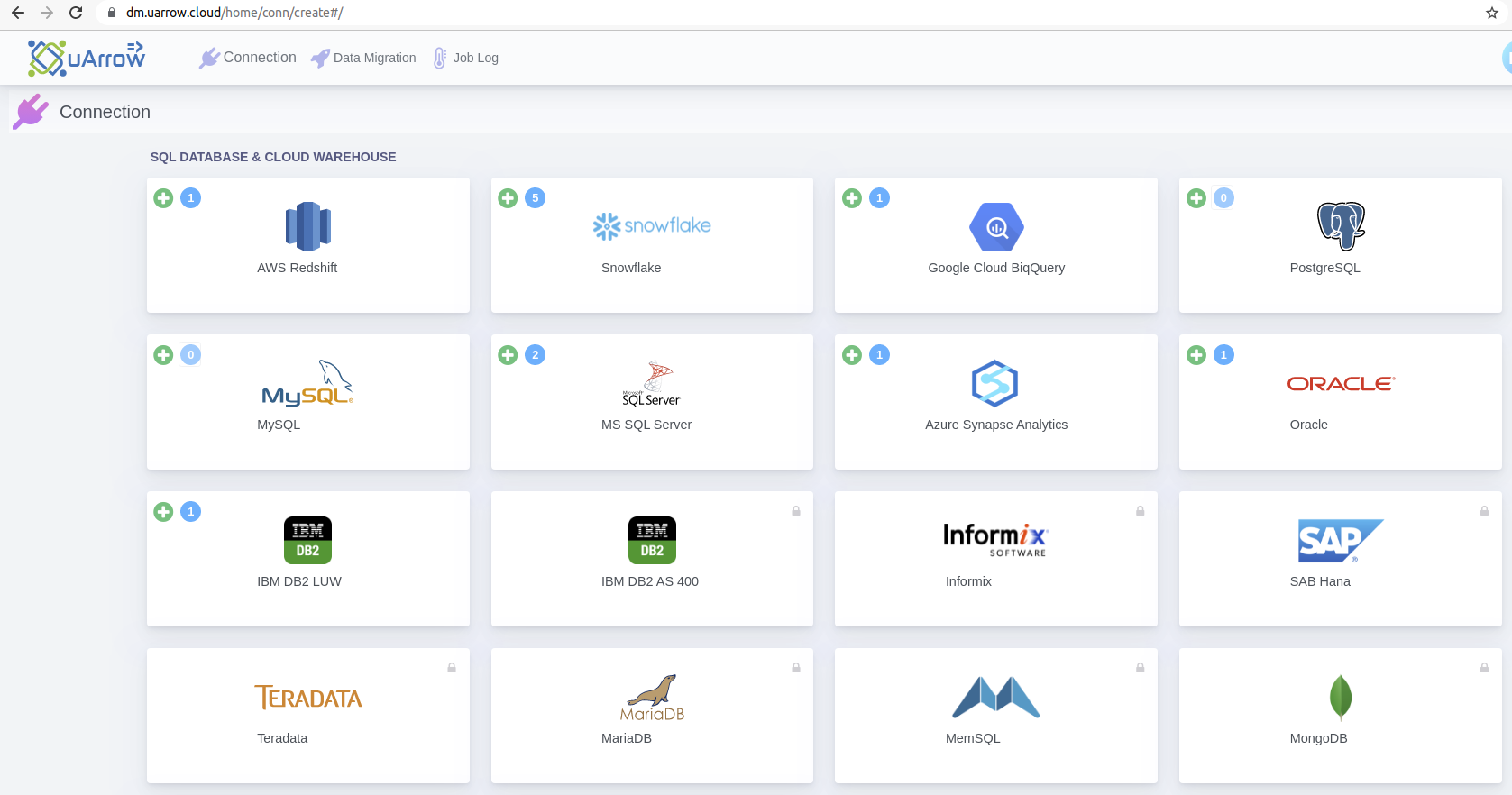
2.1. Click Connection menu from top to view (SQL DATABASE & CLOUD WAREHOUSE, CLOUD STORAGE, etc.) adapters
2.2. Click AWS Redshift button to create Redshift warehouse connection
2.3. Provide below connection parameters in the connection creation form
| Parameter Name | Description |
|---|---|
| Connection name | Specify the name of the source connection |
| Host | Enter the host name of the Redshift instance is located |
| Port | Enter the port number to connect to this Redshift account. Four digit integer, Default: 5439 |
| Database | Enter an existing Redshift database through which the uArrow accesses sources data to migrate. |
| Schema | Enter an existing Redshift database schema name. |
| User | Enter the user name of the Redshift, the user name to use for authentication on the Redshift. |
| Password | Enter the user’s password. The password to use for authentication on the Redshift |
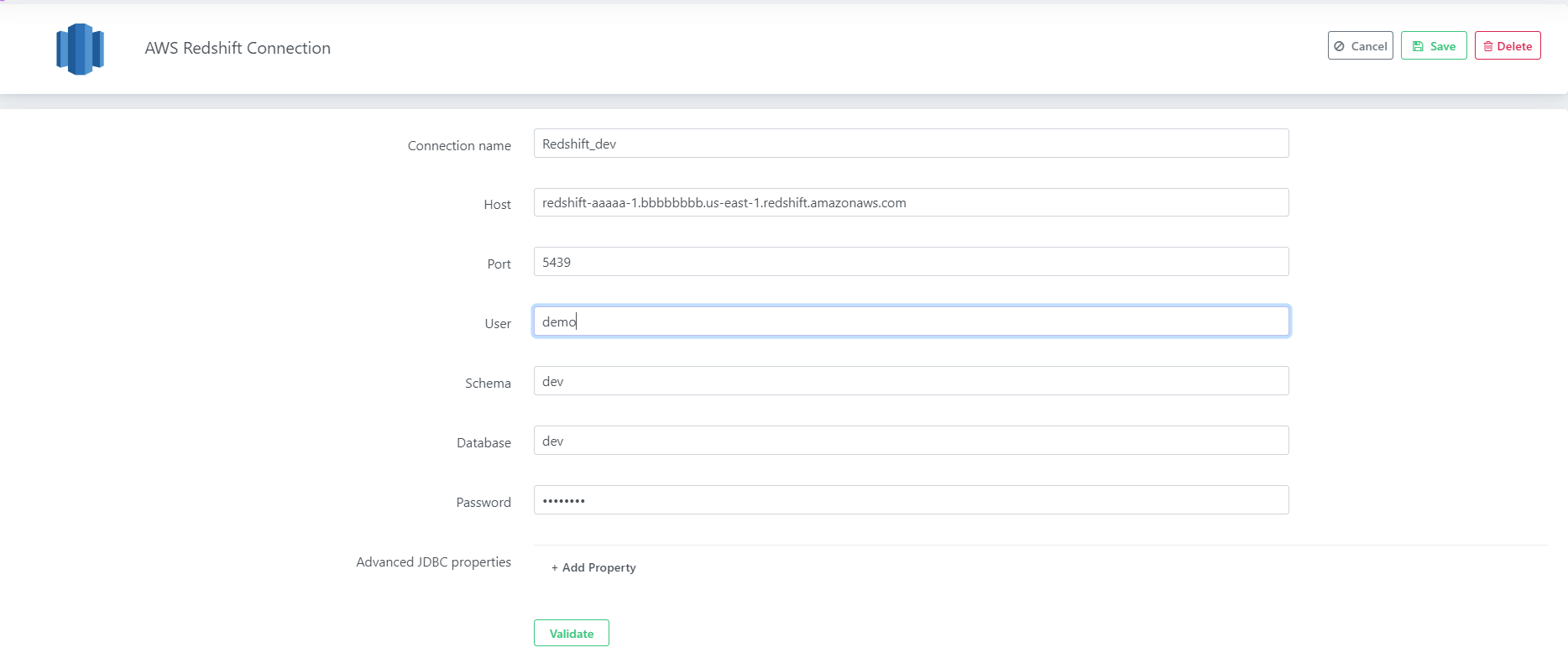
2.4.After connection details, validate connection to verify
2.5. Save Connection – Don’t forget to save connection after connection validation success
Create Job
After success full creating source, target, stage connections, you are ready to create data migration job.
- Click Data Migration menu from top to create data migration job.
- You will be able to see the below screen, there you can click on the create link to create new job.
Note: if you are already created any job you can use + button to create new data migration job.

1. Source
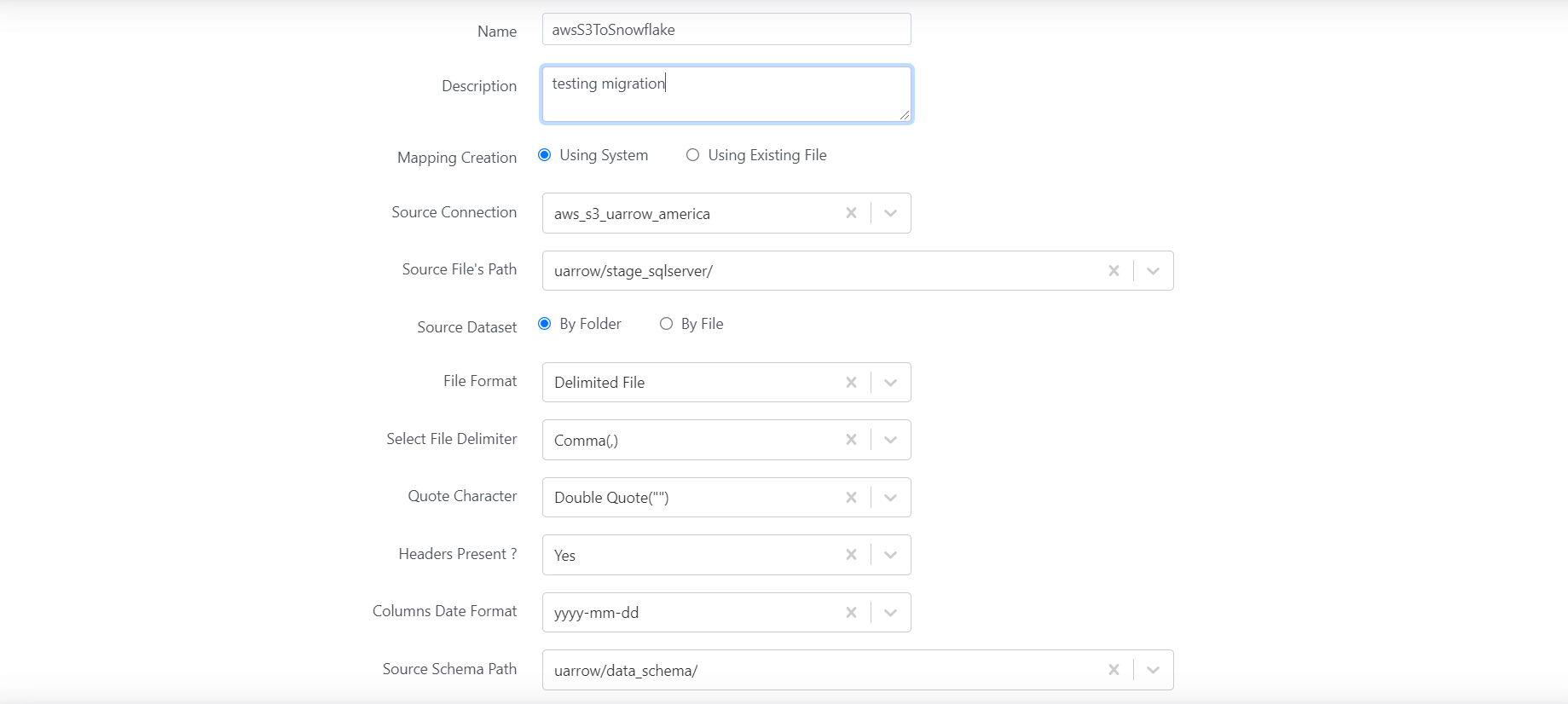
Select the AWS S3 server connection name from the drop down as the source from which the tables are to be migrated.
Click on the Through System radio button if table names to be migrated are to be selected from the system in the next screen, click on the Through existing File option if the table names to be migrated are to be uploaded via a csv file.
Select the AWS S3 connection name from the drop down menu of the Source Stage Connection option.
Select the path, where the data files are to be stored, if it is an existing path, select that path from the drop-down menu, if it is a new path that has to be created, select the Create </path/> from the drop-down menu.
Click Save followed by the Next button.
After specifying source details, Save the connection and click Next for mapping defining screen
2. Mapping
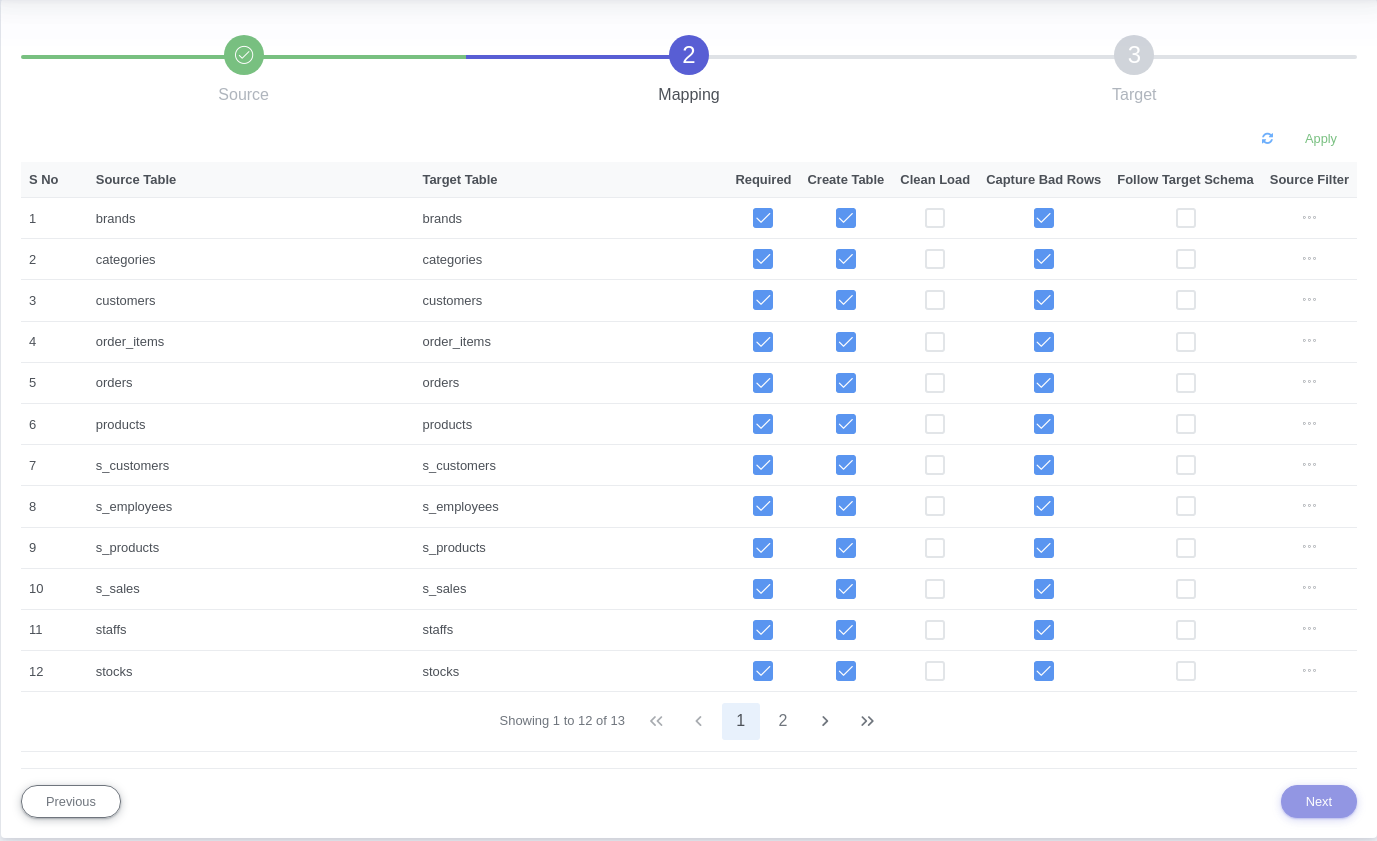
In the next screen, if the Through System radio button was selected in the previous screen, then a list of table names will pop up. Select/Deselect the Required option for each table as per requirement.
Select/Deselect the Create Table option depending on whether new tables need to be created in Redshift, similarly select/deselect the Drop table and Follow Target Schema option, depending on requirement.
Select the add filter option if any filter conditions are to be executed on the tables that are to be migrated, write the filter query in the text box provided.
Once done, click on the Apply option, followed by the Next button.
3. Target
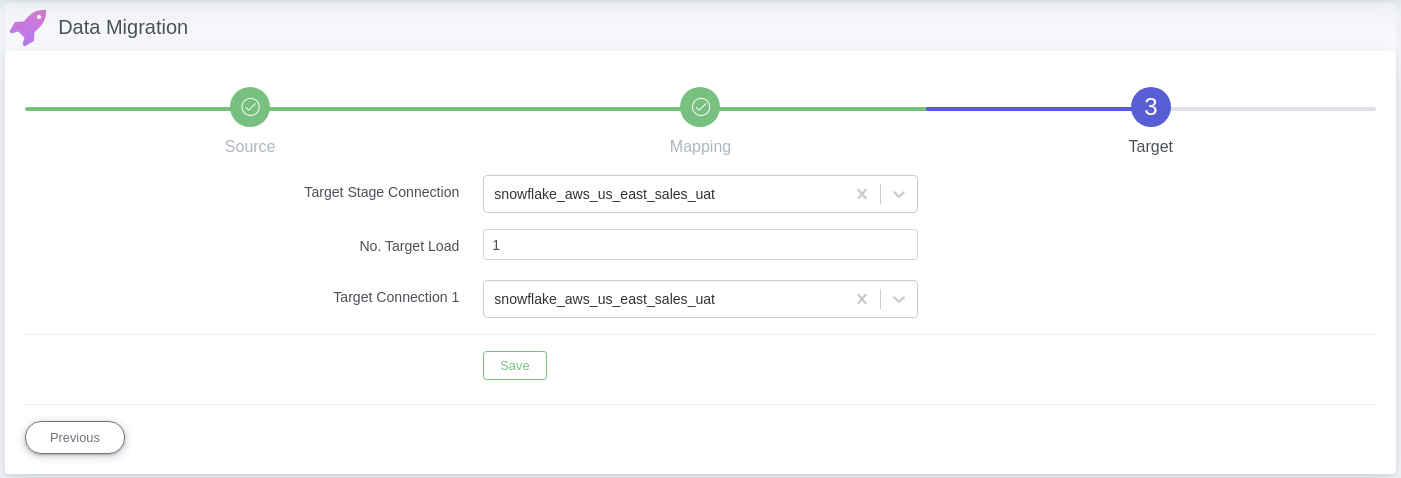
In the third screen, select any redshift connection name from the drop down menu of the Target Stage Connection, this connection is currently irrelevant for redshift databases.
Select the number of connections/targets where the data has to be migrated.
Choose the redshift connection names (depending on the number of target connections chosen), finally click ‘Save’.
Once the above mentioned Job Configuration is completed, user will be redirected to the data migration home screen, and the latest job configured will be displayed at the top of the data migration jobs list on the screen.
5. Schedule / Ad-hoc Run
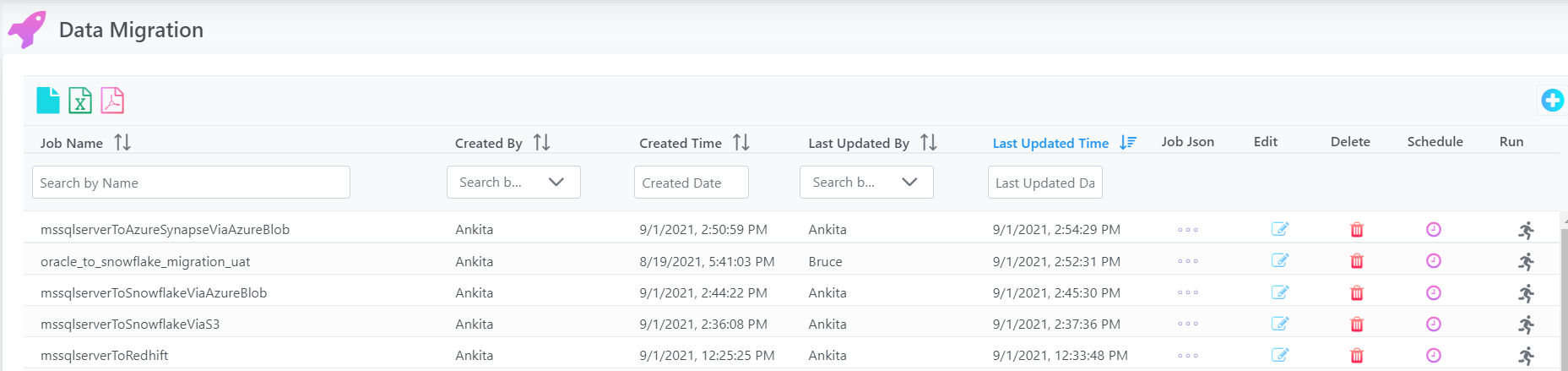
After saving the data migration job, user may run job (ad-hoc run) by clicking on the ‘Run’ icon at the right most section of the job definition row.
- After Data Migration Job is configured, click on the ‘Run’ icon at the right most section of the job definition row.
- This will instantiate Job Execution.
- System automatically starts the data migration from Source to Target.
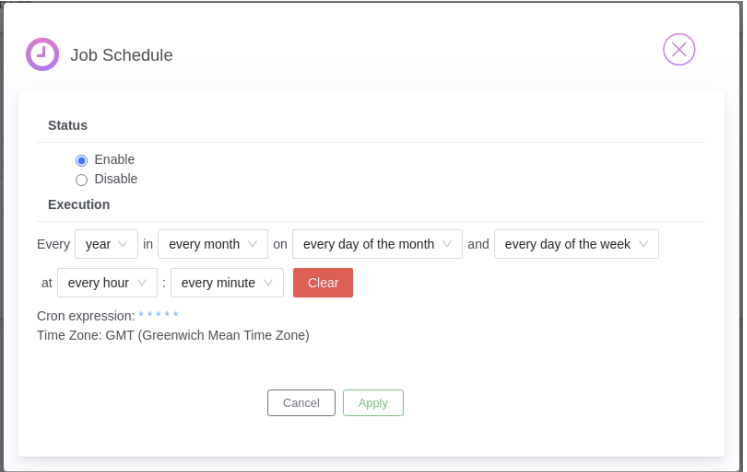
User may also schedule job if required by using Schedule icon/button to schedule existing job.
Monitoring Job
Congratulations! You have created new job for AWS S3 to Redshift Warehouse.
After successful job execution you can able to see job progress and lineage info.
Note: You can able to view job summary stats, table level detail, failed rows details for completed job.
1. Navigate to Job Log
Click Job Log menu from top to check job logs.

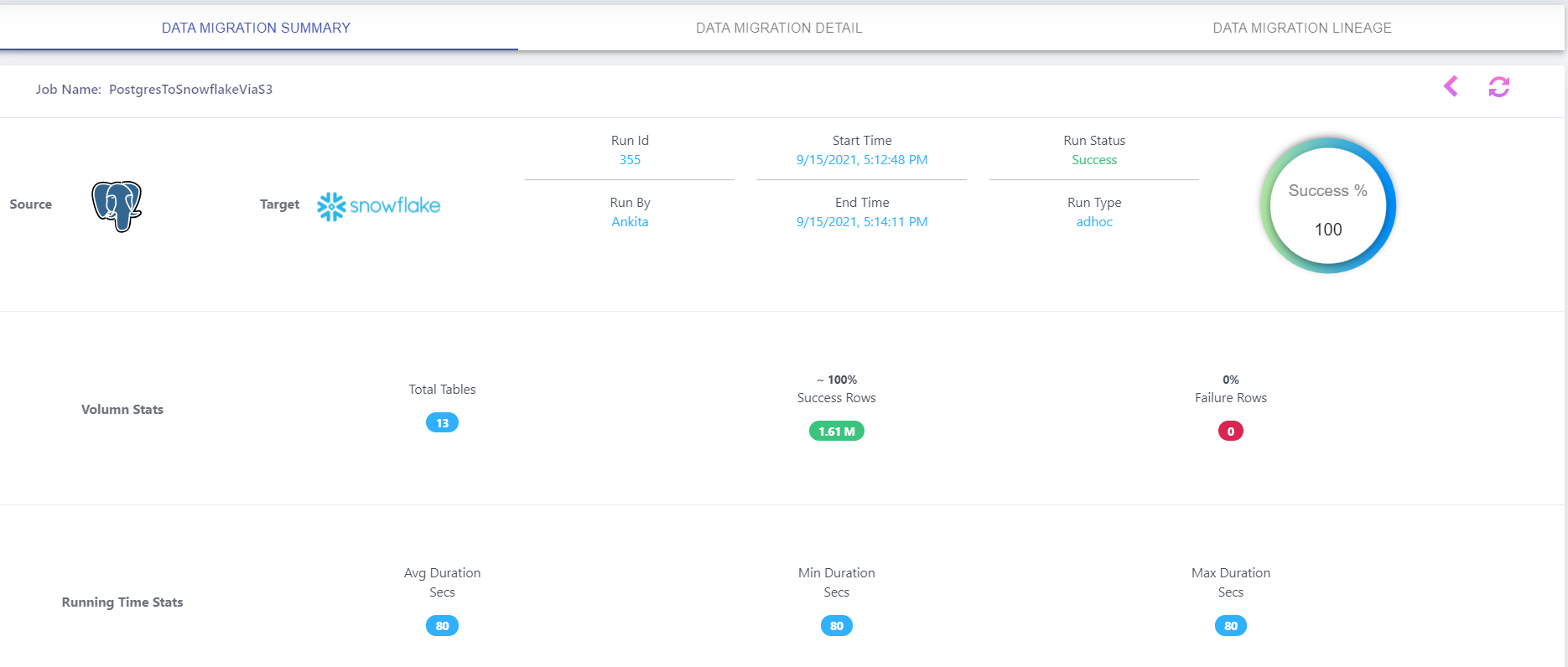
2. Summary Stats
Click on existing Job Status link/button in above screen to view job log dashboard, this will take you to Data Migration Job Log Summary screen
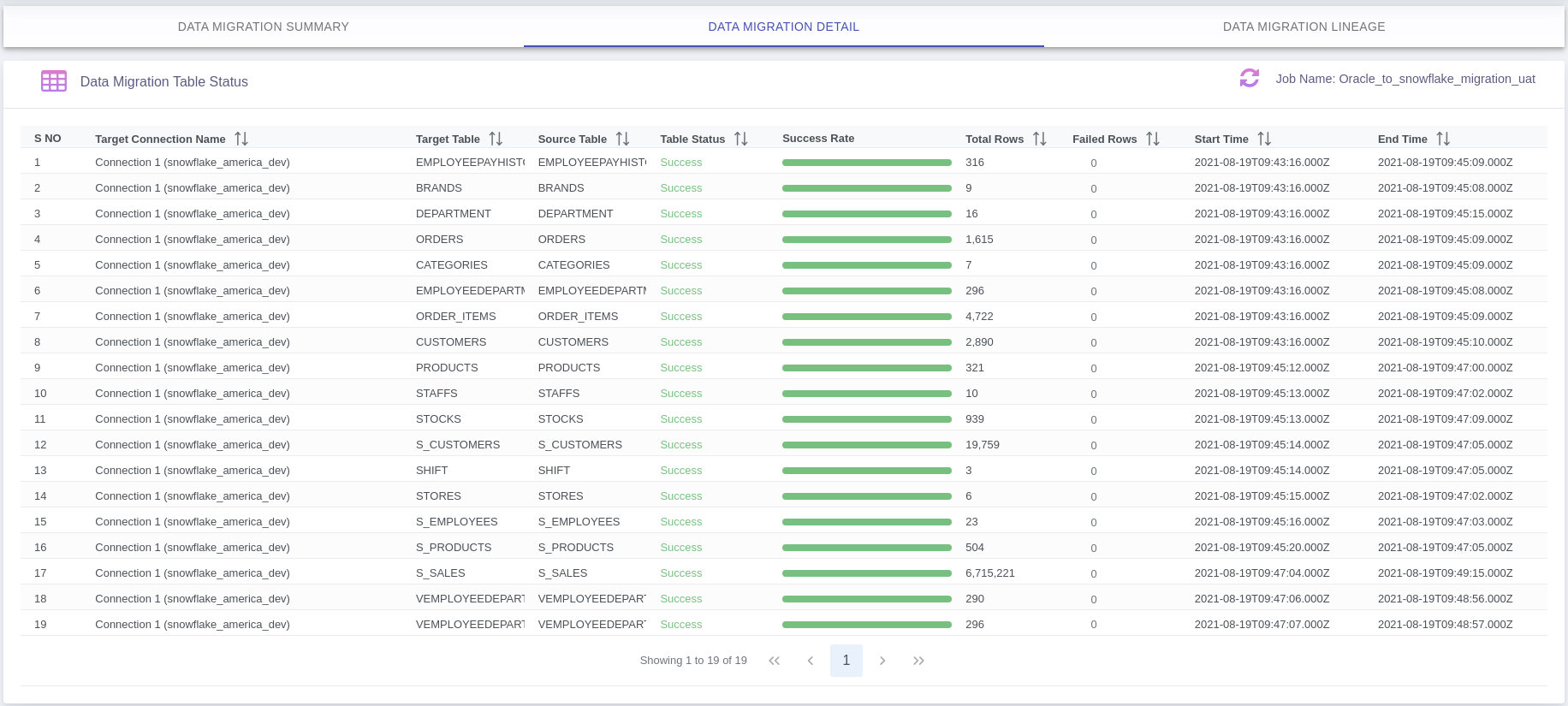
2. Detail Stats
Data Migration Table Level Status: Here you can see failed details rows clicking on Failed Rows count if any.
3. Lineage
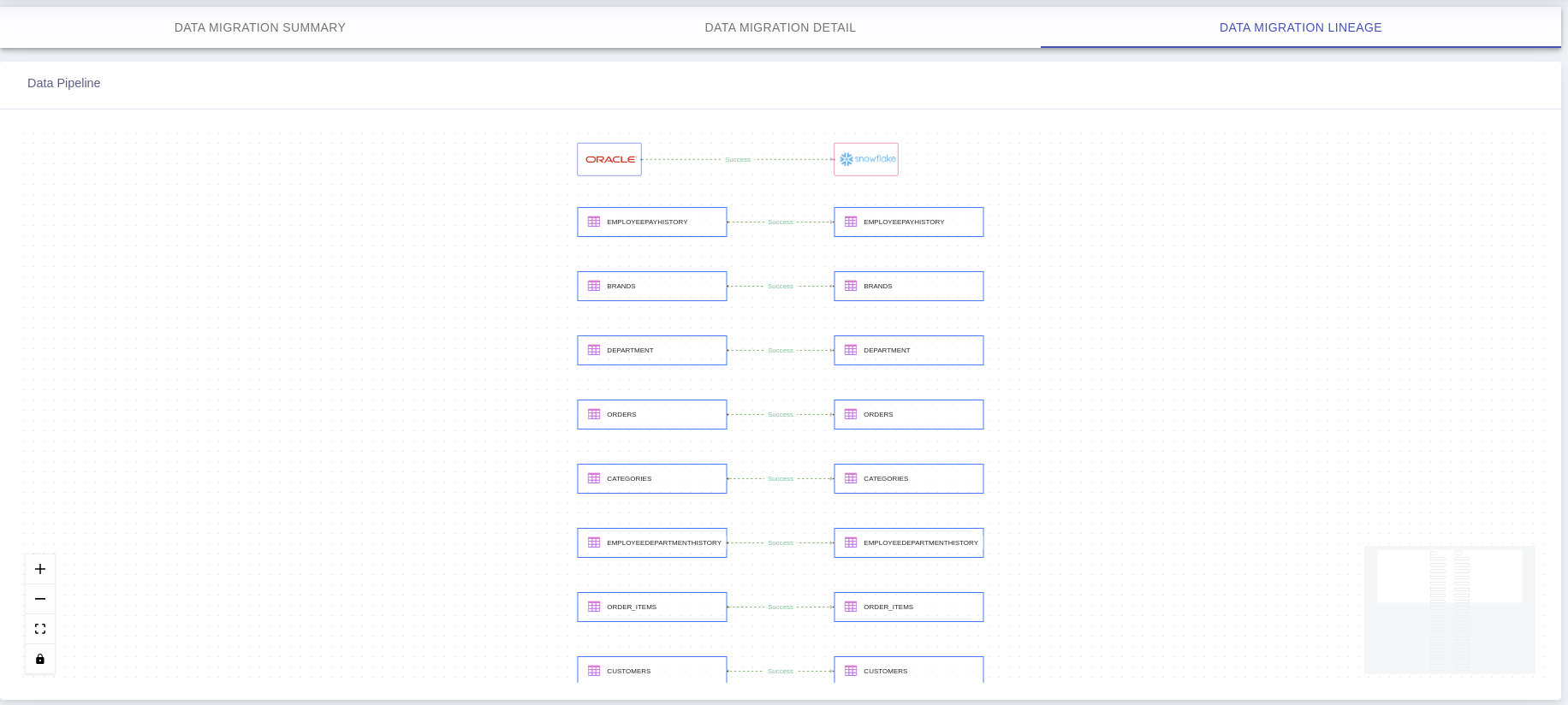
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to contact us